

The Czech Study Dashboard Is Here!
WelcomeTheEagle style reading between the lines... KABOOM! 90% of 143,958 Czechs died within one year of their last jab!


Did you know there is 143,958 DEATHS after a recorded Covid-19 injection?:

Here is a blurb from Dr. Jessica Rose showing this dashboard matches with the 11,028,372 records Jessica quotes here:
Of these 11,028,372 people, my preliminary analysis will focus on the ones who died (for which there is manufacturer-related data), since I want to compare death rates between manufacturers, and more specifically, Pfizer and Moderna. Unfortunately, as with all data sets, there are always many fields not occupied with data, so it’s not perfect. It is damned good though.
Jessica also quotes these 11M people generated 398,398 DEATHS here:
There are a total of 389,398 records that include a date of death which constitutes 3.5% of the total data set. Granted, I am not sure if this number represents all of the people who died, or simply all of the people who have death date data entered. There are 5 manufacturers listed in this dataset including Pfizer, Moderna, Astrazeneca, Janssen and Novavax, but I will focus on the modified mRNA product data.

I want to give a little explanation on these Unknown Vax Type (Unk vax name) deaths because a good part of these deaths happened in the “pre” Covid jab era with the earliest death happening on Dec 29, 2019.:

126,868 deaths happened during the pre covid jab era, while 118,573 unk vax type deaths happened in the covid jab era. I will assume some percentage of these unknown vaxxes were in fact covid jabs, but my God man this could be a game changer on this whole Czech analysis if any reasonable portion is in fact covid jabs? This data set of 398K deaths from basically January 2020 to Dec 2022 is wonky!? I’m thinking these death dates may only be just a record of death or all deaths in the Czech Republic with a covid jab record where applicable?
This is very interesting, with respects to just the reported covid jabs, all this minutiae boils down to ~6.9M people recording ~19M encounters for injections.:

I use the word “encounter” because I’m trying to distinguish between the term “doses”. Quick math might tell you 6.9M people averaged 2.72 doses totaling 19M doses but this is not the case. This little big conundrum might make me go back to the drawing board and blow this whole dashboard and start again, damn. Here is what the conundrum looks like in raw form with respects to dose counts:

Above is a sample of unique records. Some had as many as six doses, but all of them are missing at least one dosing record somewhere. The dead guy at record #2 had four jabs but is missing all details for his 2nd dose. The guy at record #7 has info on his 5th dose only. Record #9 has info on his 1st, 4th, and 5th dose but not his 2nd & 3rd dose.
See how convoluted the proper dosing count gets? Technically these nine records officially generated 21 encounters of shots, but 22 other encounters (doses) were not captured as demonstrated here in blue.:
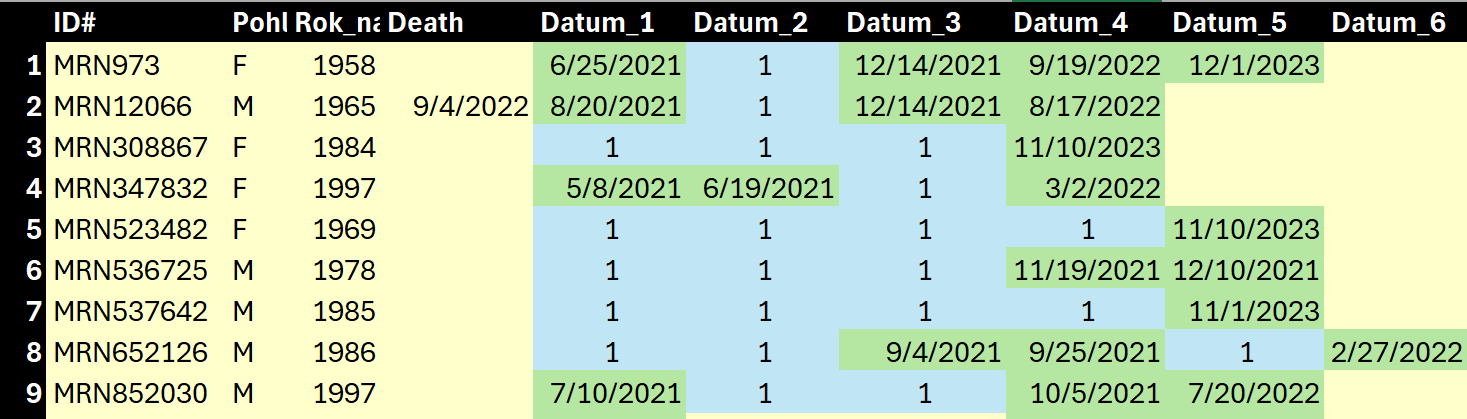
Yikes! How many people have I lost and how many people are still following? I recognized right away as I began modeling the data that I should have created a dose series field to account for the cumulative doses of each record. Also, the Czechs are comingling their cumulative doses like everybody else. It’s rather common especially with the folks who jabbed up 4 to 5 times.
Uggg! This dosing conundrum is a real brain tease. How much of these missing encounters or “doses” were also comingled? Even the one dead guy in this example had comingled dose series of Janssen & Pfizer. How proper is it to assign the death to just the last jab on the list? In VAERS this death could have been assigned to either depending on the query requested.
I think Kirsch and Rose’s analysis might be a little two dimensional? Is the law of large numbers enough to overcome the reality of comingled and missing dose series? There is another area of dump & pumping that needs to disclosed and that is the lot numbers and calling a Pfizer lot number Moderna or vice versa.
Welcome to my lot number validation tool:
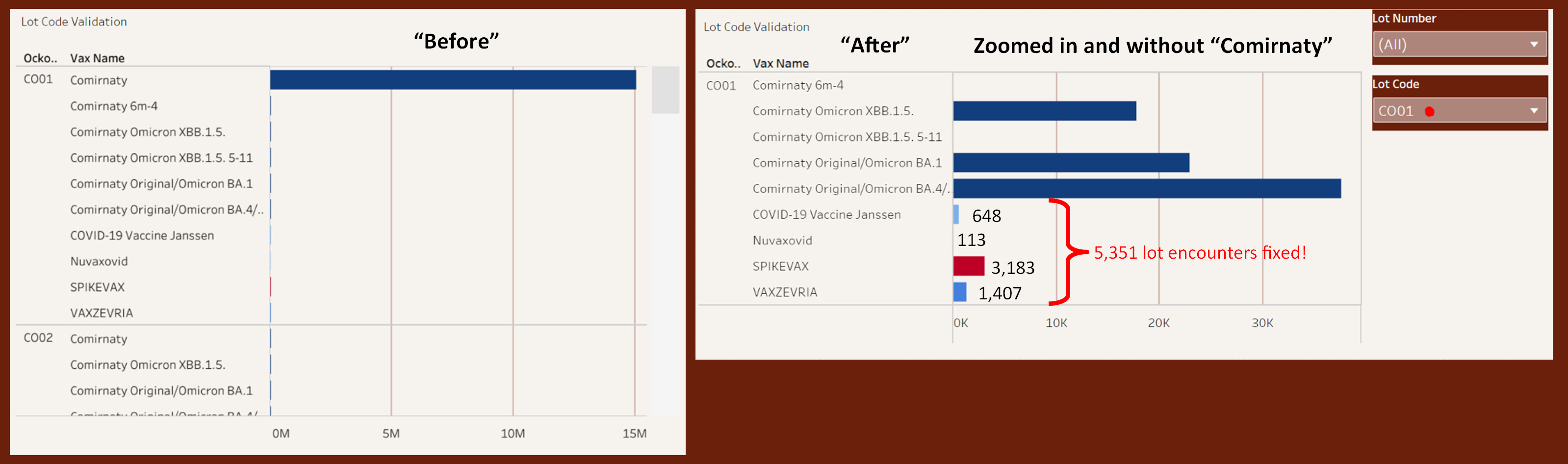
In this data a lot number is assigned a vax name and a corresponding Lot Code. The small problem here is just like VAERS where the data entry person is making a human error and mismatching lot#’s and names and lot codes in the case of the Czechs.
The example above is my validation of mostly “fixed” lot# & name mismatches. Another example below is my validation tool helping to spot lot numbers that still needs to be fixed like this Moderna lot# 090F21A:

I can see in at least a few reports the Czech data is calling this Moderna lot 090F21A a Comirnaty and Janssen.
Let it be known I’ve fixed thousands of lot numbers, name, code mismatches already. Down the road I’ll be able to calculate exactly how many, but so far I feel it’s something in the neighborhood 50K~100K lot encounters? There is a much better way of dynamically cleansing the lot, name, and code combo but I doing everything quickly and smash and grab just to get my sombrero into the ring.
I don’t know if I want to spend a ton of time figuring out which dog shit is worse Moderna or Pfizer, the thing blowing my hair back is 143,958 DEAD Czechs in a population of 10M that have died after a covid jab? Heck, 129K of 143K (90%) died with 1 year of their last jab!!
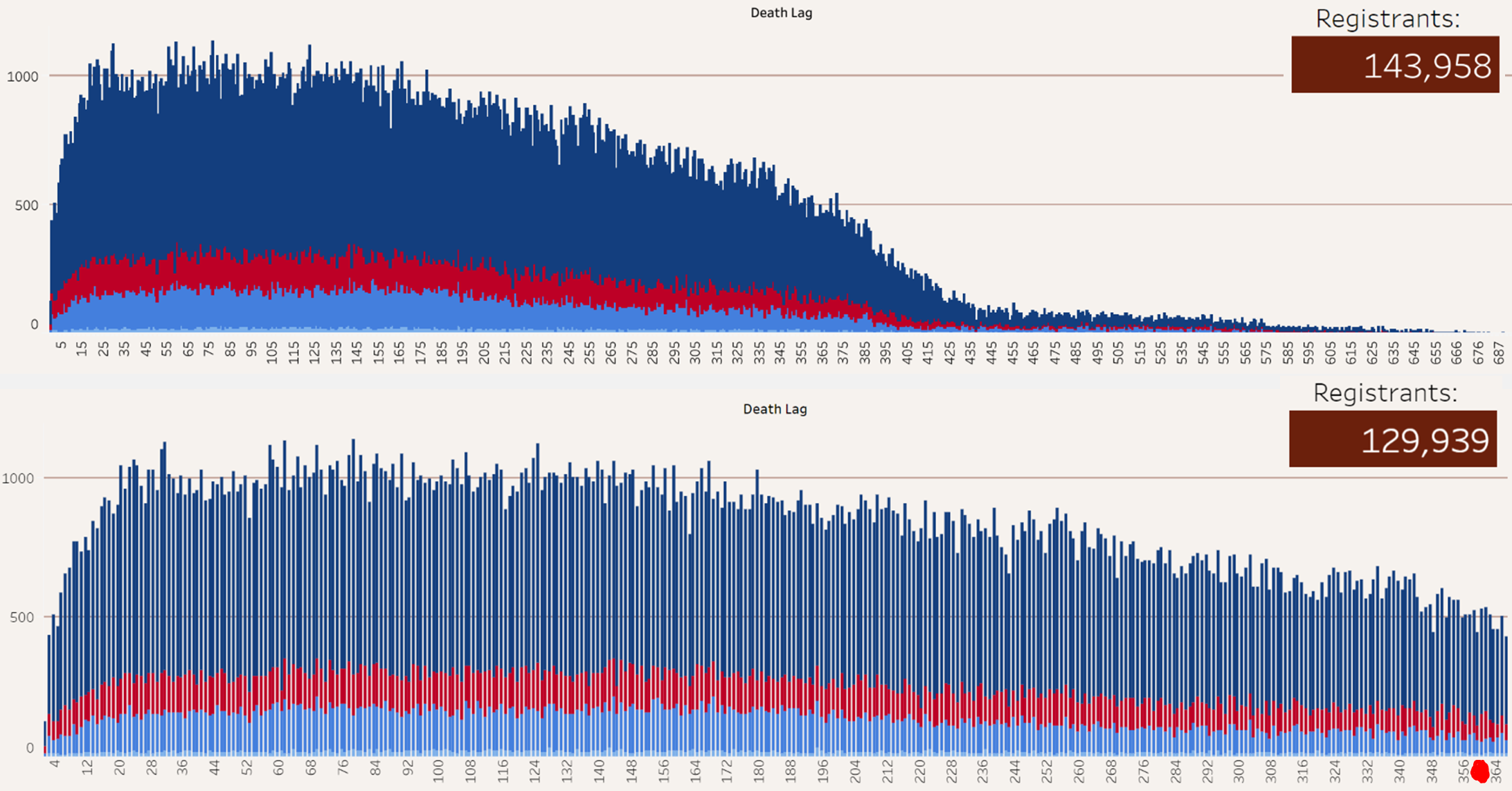
Australian PhD Geoff Pain does a good job collating other analysis and details on this Czech Study…
I’ll tell you this, Moderna looks worse than Pfizer, but AstraZeneca looks worse than Moderna.

Part 2: HERE
God Bless! Please Support The Eagle!
Dashboard here:
Jessica Rose wrote: "There are a total of 389,398 records that include a date of death which constitutes 3.5% of the total data set. Granted, I am not sure if this number represents all of the people who died, or simply all of the people who have death date data entered."
However the yearly number of deaths in the record-level CSV file is otherwise identical to the yearly number of deaths at Eurostat and in spreadsheets for deaths by ICD code published by the Czech Statistical Office, except the record-level data has a one death missing in 2021 (ec.europa.eu/eurostat/data/database, sars2.net/czech2.html#Deaths_by_ICD_code_region_age_group_and_year):
> system("wget sars2.net/f/{czicd.csv.gz,czpopdead.csv}")
> rec=fread("CR_records.csv",showProgress=F)
> icd=fread("czicd.csv.gz")[year>=2020,.(icd=sum(dead)),year]
> eurostat=fread("czpopdead.csv")[year>=2020,.(eurostat=sum(dead)),year]
> reclev=rec[,.(reclev=.N),.(year=year(DatumUmrti))]
> merge(merge(icd,eurostat),reclev)
year icd eurostat reclev
1: 2020 129289 129289 129289
2: 2021 139891 139891 139890
3: 2022 120219 120219 120219
---
The schedule for Janssen vaccines had only one primary course dose, so the fields for the second dose are blank in all people who got a Janssen vaccine for the first dose:
rec=data.table::fread("CR_records.csv")
rec[,.(mean(is.na(Datum_2),na.rm=T)*100,.N),OckovaciLatka_1][order(-N)]
There's only 15 people who have the date of the second dose listed but the date of the first dose missing, so it doesn't seem like a major problem:
> rec[is.na(Datum_1)&!is.na(Datum_2),.N]
[1] 15
> rec[is.na(Datum_1)&!is.na(Datum_3),.N]
[1] 44
---
The code below shows the average age of people based on the type of their most recent vaccine dose, so that the age is calculated based on the number of person-days that people spent under each age. The record-level data only includes the year of birth, so I assigned a random date of birth to each person. But anyway, the main reason why you got such a high rate of deaths per injection for AstraZeneca is because here my average age was about 68 for AstraZeneca, 55 for Moderna, 50 for Pfizer, and 45 for Janssen:
> b=data.table::fread("http://sars2.net/f/czbuckets.csv.gz")
> b=b[dose==0,type:="Unvaccinated"][type!=""]
> b[,.(alive=sum(as.double(alive))),.(age,type)][,.(meanage=round(weighted.mean(age,alive))),type]|[order(meanage)]>print(r=F)
type meanage
Unvaccinated 38
Other 42
Novavax 42
Janssen 45
Pfizer 50
Moderna 55
AstraZeneca 68
However when I used the 2021 census population by 5-year age groups as the standard population, I still got a higher age-standardized mortality rate for AstraZeneca than Moderna:
> std=fread("http://sars2.net/f/czcensus2021pop.csv")[,.(stdpop=sum(pop)),.(age=pmax(15,pmin(age%/%5*5,95)))]
> a=b[,.(alive=sum(alive),dead=sum(dead)),.(age=pmax(pmin(age%/%5*5,95),15),type)]
> merge(a,std)[type!="Other",.(asmr=round(sum(dead/alive*stdpop/sum(stdpop)*365e5))),type][order(-asmr)]|>print(r=F)
type asmr
Janssen 1493
Unvaccinated 1475
AstraZeneca 1231
Moderna 1067
Pfizer 861
Novavax 682
Impressive work, Welcome the Eagle!